AI-Driven Feature Selection in Python!
Deep-dive on ML techniques for feature selection in Python — Part 2
The second part of a series on ML-based feature selection where we discuss popular embedded and wrapper methods like Lasso regression, Beta coefficients, Recursive feature selection, etc.
Welcome to the second part of my blog series on ML-based feature selection! We all know that the age of Big Data is here but it is difficult to sometimes comprehend how “big” can Big Data be. I recently read an interesting blog that really put that into perspective:
- 2.5 quintillion data bytes were created daily in 2020
- At least 1.7 MB of data per second was generated by an average human in 2020
- By 2025, cloud data storage will amount to 200+ Zettabytes
Seems a little daunting right? One of the conclusions I was able to draw from this rapid rise in data size was that we can no longer use the “kitchen sink” approach to modeling. This approach simply means that we throw “everything but the kitchen sink” into the model in hopes of finding some pattern. Our models will simply not be able to make any sense of the big datasets with this approach. This is where it is crucial to use feature selection methods to throw out the noise in the data first and then proceed to develop the model.
In the first blog, we gave an overview of different types of feature selection methods and discussed a few filter methods like information value. In the second part, we will be deep-diving into the following interesting methods:
A) Beta Coefficients
B) Lasso Regression
C) Recursive Feature Selection
D) Sequential Feature Selector
The details on the dataset and the entire code (including data preparation) can be found in this Github repo. So without further ado, let’s begin!
A) Beta Coefficients
The first thing to understand about beta coefficients is that it is based on regression models. The simplest regression model is linear regression which tries to fit an equation that linearly explains the relationship between the target variable and features. It is represented as:
Y = b0 + b1*X1 + b2*X2 + b3*X3 + …. bn*Xn + u
where Y is the target variable, X1…Xn are features, b1…bn are coefficients and u is the error term. The coefficients tell us that if the features go up by 1 unit, then what is the marginal (keep all other features fixed) impact on the target variable. To deep dive into the regression model (like the assumptions, diagnostic checks, etc.), I would suggest going through the following:
- A Refresher on Regression Analysis
- Linear regression assumptions
- Introduction to Multivariate Regression Analysis
- Basic Econometrics (Chapter 2–13) (Covers all the regression-related topics in depth)
Why do we standardize features?
One interesting thing to note about the coefficients is that they are influenced by the scale of the features. For example, if our target is GDP and the features are budget deficit in million rupees and central bank repo rate in %, we cannot compare the coefficients to say which feature has a higher impact on GDP. To make the coefficients comparable, we need to standardize the features. Standardizing a feature involves the following steps:
- Calculate the mean(average) of the feature
- Calculate the standard deviation of the feature
- For each observation, deduct the mean and then divide by the standard deviation
After standardizing, each feature has a mean of 0 and a standard deviation of 1 and hence becomes comparable. The coefficients of such standardized features are called beta coefficients. We can sort the features by the absolute value of beta coefficients and pick the top n features (n can be decided by the developer based on business context and degrees of freedom).
Beta coefficients for logistic regression:
The regression model we mentioned earlier is a linear regression model that can predict only continuous variables. To calculate beta coefficients for classification problems we need to use Logistic regression. It can be represented as:
ln(pi/(1-pi)) = b0 + b1*X1 + b2*X2 + b3*X3 + …. bn*Xn + u
where everything remains the same except that instead of predicting the target variable (which will have different classes like event and non-event), the coefficients tell us that if the features go up by 1 unit, then what is the marginal impact on the log of odds of the target variable.
For example, let’s assume our target is whether the government is going to default and the features are budget deficit in million rupees and central bank repo rate in %. The budget deficit coefficient tells us if the deficit goes up by 1 million rupees, then what is the marginal impact on the logarithm of odds of the government defaulting i.e log(probability of default/probability of non-default).
Although there are a number of other differences between Logistic and Linear regression (like linear regression is calculated using OLS while logistic regression uses maximum likelihood estimation due to non-linearity in the latter), we will not deep dive into them here. For more details on Logistic regression, I would suggest going through the following:
- What is logistic regression?
- Maximum Likelihood Estimation of logistic regression
- Detailed overview
- Basic Econometrics (Chapter 15)
- Beta coefficients for Logistic
Python function for calculating beta coefficients for Logistic regression:
For calculating beta coefficients using logistic regression, we first use the StandardScaler function to standardize the dataset and then use LogisticRegression function from the scikit-learn package to fit a logistic regression with no penalty term and intercept. The function beta_coeffcalculates the beta coefficients for each feature and also selects the top n (n provided by the user as the parameter beta_threshold ) features based on the absolute value of the beta coefficient. It then fits another lasso regression with the selected features to allow developers to see how the regression is behaving with selected features (like sign and significance of features).
#3. Select the top n features based on absolute value of beta coefficient of features# Beta Coefficientsbeta_threshold = 10################################ Functions #############################################################def beta_coeff(data, train_target,beta_threshold):
#Inputs
# data - Input feature data
# train_target - Target variable training data
# beta_threshold - select n features with highest absolute beta coeficient value
# Standardise dataset scaler = StandardScaler()
data_v2 = pd.DataFrame(scaler.fit_transform(data))
data_v2.columns = data.columns# Fit Logistic on Standardised dataset
# Manual Change in Parameters - Logistic Regression
# Link to function parameters - https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
log = LogisticRegression(fit_intercept = False, penalty = 'none')
log.fit(data_v2, train_target)
coef_table = pd.DataFrame(list(data_v2.columns)).copy()
coef_table.insert(len(coef_table.columns), "Coefs", log.coef_.transpose())
coef_table = coef_table.iloc[coef_table.Coefs.abs().argsort()]
sr_data2 = coef_table.tail(beta_threshold)
beta_top_features = sr_data2.iloc[:,0].tolist()
print(beta_top_features)
beta_top_features_df = pd.DataFrame(beta_top_features,columns = ['Feature'])
beta_top_features_df['Method'] = 'Beta_coefficients' log_v2 = sm.Logit(train_target,\
sm.add_constant(data[beta_top_features])).fit()
print('Logistic Regression with selected features')
print(log_v2.summary())
return log,log_v2,beta_top_features_df################################ Calculate Beta Coeff ################################################standardised_logistic,logistic_beta_features,beta_top_features_df = beta_coeff(train_features_v2,train_target,beta_threshold)beta_top_features_df.head(n=20)
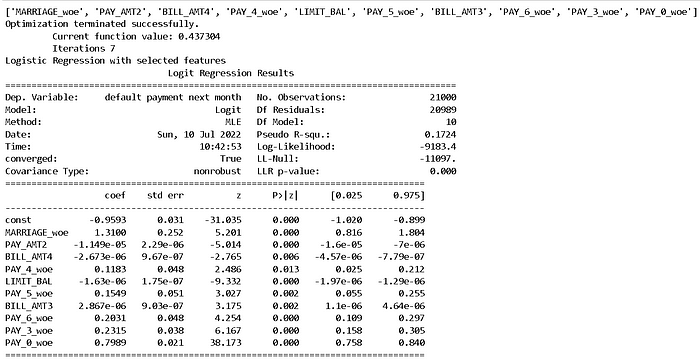
The code for calculating beta coefficients for linear regression can be found here.
B) Lasso Regression
Lasso regression is one of the few embedded methods available for feature selection. It is a natural extension of linear/logistic regression where a penalty term is used to select the features. The cost function (the function that needs to be minimized to get optimal coefficient values) of lasso regression can be represented as:
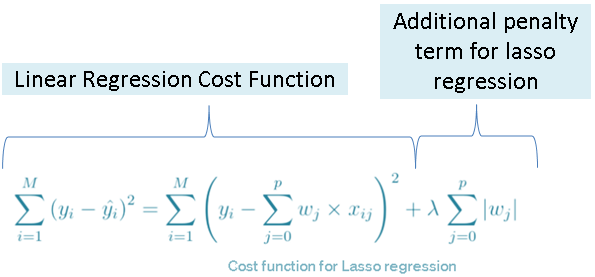
The additional penalty term is essentially the absolute sum of the coefficients multiplied by a factor (called the tuning parameter which we will discuss shortly) and this process is called L1 regularization. So as we keep increasing features, we will keep adding the coefficients of the features to the penalty term which will increase the cost. This type of regularization (L1) leads to zero coefficients for some of the least important features and hence, we can select features using this model (to learn more about regularization, check this blog). Also, the same penalty term can be applied to the logistic regression cost function to select the features.
Setting the tuning parameter
The main thing to consider while using L1 regularization is the value of the tuning parameter λ as it controls the strength of the penalty. As can be seen from the equation, setting it to 0 is equivalent to linear regression. One way to set up the tunning parameter is to try out a range of values, build a regression for each, and select the one with the lowest AIC score. One can start by testing values between 0.01 and 1.0 with a grid separation of 0.01.
For further details on lasso regression, one can go through the following lecture slides.
Python function for adding L1 regularization to Logistic Regression (Lasso with Logistic regression):
The function lassofits a logistic regression with l1 penalty term with the tuning parameter value provided by the user as the parameter lasso_param. Similar to the previous function, it then fits another lasso regression with the selected features.
#4. Select the features identified by Lasso regression# Lassolasso_param = .01################################ Functions #############################################################def lasso(data, train_target,lasso_param):
#Inputs
# data - Input feature data
# train_target - Target variable training data
# lasso_param - Lasso l1 penalty term
#Fit Logistic
# Manual Change in Parameters - Logistic Regression
# Link to function parameters - https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
log = LogisticRegression(penalty ='l1', solver = 'liblinear',\
C = lasso_param)
log.fit(data, train_target)
#Select Features
lasso_df = pd.DataFrame(columns = ['Feature', 'Lasso_Coef'])
lasso_df['Feature'] = data.columns
lasso_df['Lasso_Coef'] = log.coef_.squeeze().tolist()
lasso_df_v2 = lasso_df[lasso_df['Lasso_Coef'] !=0]
lasso_top_features = lasso_df_v2['Feature'].tolist()
lasso_top_features_df = pd.DataFrame(lasso_top_features,\
columns = ['Feature'])
lasso_top_features_df['Method'] = 'Lasso'# Logistic Regression with selected features
log_v2 = sm.Logit(train_target,\
sm.add_constant(data[lasso_top_features])).fit()
print('Logistic Regression with selected features')
print(log_v2.summary())
return log_v2,lasso_top_features_df################################ Calculate Lasso ################################################logistic_lasso_features,lasso_top_features_df = lasso(train_features_v2,train_target,lasso_param)lasso_top_features_df.head(n=20)
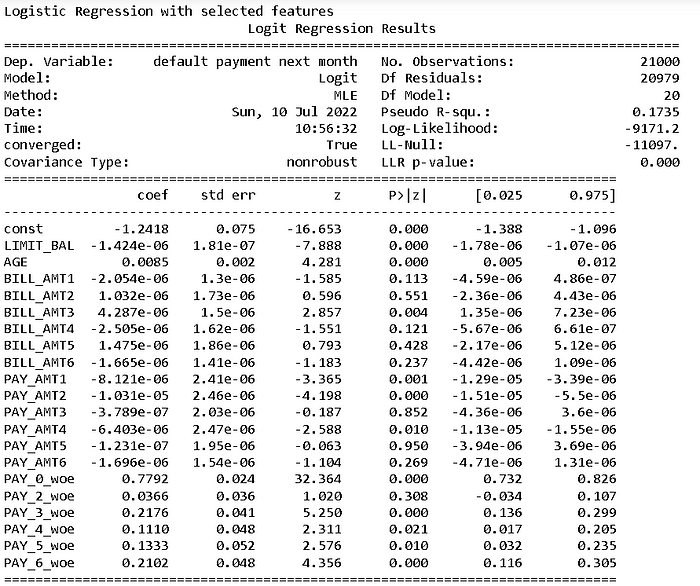
The same function can be easily used for linear regression by changing LogicticRegression function with LinearRegression and Logit with OLS
C) Recursive Feature Elimination (RFE)
This is one of the two popular feature selection methods provided by Scikit-learnpackage of python for feature selection. Although RFE is technically a wrapper-style method internally it is based on the process used by filter-based methods. Let’s see how.
How does RFE work?
- RFE first trains the user-defined model on the entire set of features. The user-defined model can be any supervised learning estimator with a
fitmethod that provides information about feature importance. - It then calculates the importance of each feature from the trained model. The importance can be obtained either through any model-specific attribute (such as
coef_,feature_importances_) or a user-defined metric that can be calculated for each feature. - It then discards the least important feature and then repeats steps 1 and 2 with the reduced number of features
- Step 3 is repeated till the user-defined number of features remain
RFE is considered a wrapper method because it is “wrapped” around an external estimator. But it is also based on the principles of the filter-based method due to ranking of features based on a measure of importance.
How to automatically pick the number of features using RFE?
Picking the number of features is not straightforward and thankfully Scikit-learnpackage has a new function calledRFECV (Recursive feature elimination with cross-validation)which relieves us from this burden. Cross-validation is a model performance testing strategy and the most popular version is k-fold cross-validation. We first split data into k random parts, then train the model on all but one (k-1) of the parts, and finally, evaluate the model on the part that was not used for training. This is repeated k times, with a different part reserved for evaluation each time.
If we have n features, RFECV essentially performs RFE along with cross-validation n-1 times (Dropping the least important feature in each iteration). It then picks the number of features for which the cross-validation score is maximized.
Python function for implementing RFECV:
We are using RFECV function from scikit-learn here which is configured just like the RFE class regarding the choice of the algorithm. The function rfecv_feature_selection allows users to pick from 5 popular tree based algorithms : XG Boost, Random Forest, Catboost, Light GBM and Decision Tree. I will be writing a new blog series on each of the methods soon. The function sets up any estimator from the list specified by the user using the rfe_estimator parameter. If nothing is mentioned, a decision tree is fit by default. They can also change a number of other features like scoring metrics to select optimal number of features (see inputs section of the function in the code below).
#5. Select features based on Recursive Feature Selection method# RFECVrfe_estimator = "XGBoost"
rfe_step = 2
rfe_cv = 5
rfe_scoring = 'f1'################################ Functions #############################################################def rfecv_feature_selection(data, train_target,rfe_estimator,rfe_step,rfe_cv,rfe_scoring):
#Inputs
# data - Input feature data
# train_target - Target variable training data
# rfe_estimator - base model (default: Decision Tree)
# rfe_step - number of features to remove at each iteration
# rfe_cv - cross-validation splitting strategy
# rfe_scoring - CV performance scoring metric## Initialize RFE if rfe_estimator == "XGBoost":
# Manual Change in Parameters - XGBoost
# Link to function parameters - https://xgboost.readthedocs.io/en/stable/parameter.html
estimator_rfe = XGBClassifier(n_jobs = -1, random_state=101)
elif rfe_estimator == "RandomForest":
# Manual Change in Parameters - RandomForest
# Link to function parameters - https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
estimator_rfe = RandomForestClassifier(n_jobs = -1, random_state=101)
elif rfe_estimator == "CatBoost":
# Manual Change in Parameters - CatBoost
# Link to function parameters - https://catboost.ai/en/docs/concepts/python-reference_catboostclassifier
estimator_rfe = CatBoostClassifier(iterations=50,verbose=0,random_state=101)
elif rfe_estimator == "LightGBM":
# Manual Change in Parameters - LightGBM
# Link to function parameters - https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.LGBMClassifier.html
estimator_rfe = lgb.LGBMClassifier(n_jobs = -1, random_state=101)
else:
# Manual Change in Parameters - DecisionTree
# Link to function parameters - https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
estimator_rfe = DecisionTreeClassifier(random_state=101)# Fit RFECV
# Manual Change in Parameters - RFECV
# Link to function parameters - https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.RFECV.html
# Scoring metrics - https://scikit-learn.org/stable/modules/model_evaluation.html
rfecv = RFECV(estimator = estimator_rfe, step = rfe_step, cv = rfe_cv, scoring = rfe_scoring)
rfecv.fit(data, train_target)# Select feature based on RFE
print('Optimal number of features: {}'.format(rfecv.n_features_))
rfe_df = pd.DataFrame(columns = ['Feature', 'rfe_filter'])
rfe_df['Feature'] = data.columns
rfe_df['rfe_filter'] = rfecv.support_.tolist()
rfe_df_v2 = rfe_df[rfe_df['rfe_filter']==True]
rfe_top_features = rfe_df_v2['Feature'].tolist()
print(rfe_top_features)
rfe_top_features_df = pd.DataFrame(rfe_top_features,columns = ['Feature'])
rfe_top_features_df['Method'] = 'RFECV'# Plot CV results
%matplotlib inline
plt.figure(figsize=(16, 9))
plt.title('Recursive Feature Elimination with Cross-Validation', fontsize=18, fontweight='bold', pad=20)
plt.xlabel('Number of features selected', fontsize=14, labelpad=20)
plt.ylabel('f1 acore', fontsize=14, labelpad=20)
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_, color='#303F9F', linewidth=3) plt.show()
return rfe_top_features_df,rfecv################################ Calculate RFECV #############################################################rfe_top_features_df,rfecv = rfecv_feature_selection(train_features_v2,train_target,rfe_estimator,rfe_step,rfe_cv,rfe_scoring)
rfe_top_features_df.head(n=20)

I personally do not use RFECV with regression models as ranking features based on coefficient values is not advisable if the features are not on the same scale.
D) Sequential Feature Selection (SFS)
Sequential Feature Selection (SFS)is the other wrapper-type feature selection method provided by Scikit-learnpackage. The difference between RFE and SFS is that it does not require the underlying model to calculate a feature importance score. It also has the flexibility to do both forward (starting with 1 feature and adding features to the model subsequently) or backward (starting with all features and removing features to the model subsequently) feature selection while RFE can only do the backward selection.
Additionally, SFS is usually slower than RFECV. For example, in the backward selection, the iteration going from n features to n-1 features using k-fold cross-validation requires fitting n*k models, while RFECV would require only k fits.
How does SFS work?
Forward-SFS:
- SFS initially starts with no features and finds the feature which maximizes a cross-validation score
- Once the first feature is selected, SFS repeats the process by adding a new feature to the existing selected feature.
- The procedure continues till the desired number of selected features is reached, as determined by the
n_features_to_selectparameter. If the user doesn’t specify the exact number of features to select or a threshold of improvement in performance, the algorithm selects half of the existing list of features automatically.
Backward-SFS:
It has the same process but works in the opposite direction: it starts with all the features and then starts removing features from the set.
How to select the direction (Backward vs Forward)?
The direction parameter controls whether forward or backward SFS is used. It is also important to note that forward and backward selection usually do not yield equivalent results. We should select the direction based on what % of the features we want to keep in the model. If we want to keep the majority of the features, we should select ‘Backward’ and vice-versa.
Python function for implementing SequentialFeatureSelector:
We are using SequentialFeatureSelector function from scikit-learn here. The function sfs_feature_selection fits a logistic regression. I used logistic regression here as we can choose the features based on their impact on r-squared and we are already fitting tree-based models in the previous method. The user can also change a number of features like the number of features to keep (see inputs section of the function in the code below).
#6. Select features based on Sequential Feature Selector# Sequential Feature Selectorsfs_feature = 10
sfs_direction = 'backward'
sfs_cv = 2
sfs_scoring = 'r2'################################ Functions #############################################################def sfs_feature_selection(data, train_target,sfs_feature,sfs_direction,sfs_cv,sfs_scoring):
#Inputs
# data - Input feature data
# train_target - Target variable training data
# sfs_feature - no. of features to select
# sfs_direction - forward and backward selection
# sfs_cv - cross-validation splitting strategy
# sfs_scoring - CV performance scoring metric logistic = LogisticRegression(penalty = None) sfs=SequentialFeatureSelector(estimator = logistic,
n_features_to_select=sfs_feature,
direction = sfs_direction,
cv = sfs_cv,
scoring = sfs_scoring)
sfs.fit(train_features_v2, train_target)
sfs.get_support() sfs_df = pd.DataFrame(columns = ['Feature', 'SFS_filter'])
sfs_df['Feature'] = train_features_v2.columns
sfs_df['SFS_filter'] = sfs.get_support().tolist() sfs_df_v2 = sfs_df[sfs_df['SFS_filter']==True]
sfs_top_features = sfs_df_v2['Feature'].tolist()
print(sfs_top_features)
x_temp = sm.add_constant(train_features_v2[sfs_top_features]) log_v2=sm.Logit(train_target,x_temp).fit() print(log_v2.summary())
sfs_top_features_df=pd.DataFrame(sfs_top_features\
,columns = ['Feature'])
sfs_top_features_df['Method']='Sequential_feature_selector' return sfs_top_features_df,sfs################################ Calculate RFECV #############################################################sfs_top_features_df,sfs = sfs_feature_selection(train_features_v2,train_target,sfs_feature,sfs_direction,sfs_cv,sfs_scoring)
sfs_top_features_df.head(n=20)

As mentioned previously, the user can fit any other method here by making changes to this section of the code:
sfs=SequentialFeatureSelector(estimator = #add model here#
,n_features_to_select=sfs_feature,
direction = sfs_direction,
cv = sfs_cv,
scoring = sfs_scoring)Final Words
We have now come to the end of Part 2 of the 3-part blog series. The readers should now be familiar with 6 different feature selection techniques. They should also be aware of the best practices associated with them along with their python implementation. I would like to highlight here that feature selection is a combination of art and science. Although we have discussed the science behind it in detail, one becomes better at it with experience.
Do read the final part of this series where we discuss the most advanced techniques available at our disposal (Borutapy, Borutashap) and discuss how to combine all these methods. Finally, the entire code for the analysis can be found here.
Do you have any questions or suggestions about this blog? Please feel free to drop in a note.
Reference Material
- A Refresher on Regression Analysis
- Linear regression assumptions
- Introduction to Multivariate Regression Analysis
- Basic Econometrics (Chapter 2–13) (Covers all the regression-related topics in depth)
- What is logistic regression?
- Maximum Likelihood Estimation of logistic regression
- Detailed overview
- Basic Econometrics (Chapter 15)
- Beta coefficients for Logistic
Let’s Connect!
If you, like me, are passionate about AI, Data Science or Economics, please feel free to add/follow me on LinkedIn, Github and Medium.
